diff --git a/notebooks/Migration to Direct Lake.ipynb b/notebooks/Migration to Direct Lake.ipynb
index 640891e1..5e832ecd 100644
--- a/notebooks/Migration to Direct Lake.ipynb
+++ b/notebooks/Migration to Direct Lake.ipynb
@@ -1 +1,387 @@
-{"cells":[{"cell_type":"markdown","id":"5c27dfd1-4fe0-4a97-92e6-ddf78889aa93","metadata":{"nteract":{"transient":{"deleting":false}}},"source":["### Install the latest .whl package\n","\n","Check [here](https://pypi.org/project/semantic-link-labs/) to see the latest version."]},{"cell_type":"code","execution_count":null,"id":"d5cae9db-cef9-48a8-a351-9c5fcc99645c","metadata":{"jupyter":{"outputs_hidden":true,"source_hidden":false},"nteract":{"transient":{"deleting":false}}},"outputs":[],"source":["%pip install semantic-link-labs"]},{"cell_type":"markdown","id":"969a29bf","metadata":{},"source":["### Import the library and set initial parameters"]},{"cell_type":"code","execution_count":null,"id":"29c923f8","metadata":{},"outputs":[],"source":["import sempy_labs as labs\n","from sempy_labs import migration, directlake\n","import sempy_labs.report as rep\n","\n","dataset_name = '' #Enter the import/DQ semantic model name\n","workspace_name = None #Enter the workspace of the import/DQ semantic model. It set to none it will use the current workspace.\n","new_dataset_name = '' #Enter the new Direct Lake semantic model name\n","new_dataset_workspace_name = None #Enter the workspace where the Direct Lake model will be created. If set to None it will use the current workspace.\n","lakehouse_name = None #Enter the lakehouse to be used for the Direct Lake model. If set to None it will use the lakehouse attached to the notebook.\n","lakehouse_workspace_name = None #Enter the lakehouse workspace. If set to None it will use the new_dataset_workspace_name."]},{"cell_type":"markdown","id":"5a3fe6e8-b8aa-4447-812b-7931831e07fe","metadata":{"nteract":{"transient":{"deleting":false}}},"source":["### Create the [Power Query Template](https://learn.microsoft.com/power-query/power-query-template) file\n","\n","This encapsulates all of the semantic model's Power Query logic into a single file."]},{"cell_type":"code","execution_count":null,"id":"cde43b47-4ecc-46ae-9125-9674819c7eab","metadata":{"jupyter":{"outputs_hidden":false,"source_hidden":false},"nteract":{"transient":{"deleting":false}}},"outputs":[],"source":["migration.create_pqt_file(dataset = dataset_name, workspace = workspace_name)"]},{"cell_type":"markdown","id":"bf945d07-544c-4934-b7a6-cfdb90ca725e","metadata":{"nteract":{"transient":{"deleting":false}}},"source":["### Import the Power Query Template to Dataflows Gen2\n","\n","- Open the [OneLake file explorer](https://www.microsoft.com/download/details.aspx?id=105222) and sync your files (right click -> Sync from OneLake)\n","\n","- Navigate to your lakehouse. From this window, create a new Dataflows Gen2 and import the Power Query Template file from OneLake (OneLake -> Workspace -> Lakehouse -> Files...), and publish the Dataflows Gen2.\n","\n","\n","Important! Make sure to create the Dataflows Gen2 from within the lakehouse window. That will ensure that all the tables automatically map to that lakehouse as the destination. Otherwise, you will have to manually map each table to its destination individually.\n","
"]},{"cell_type":"markdown","id":"9975db7d","metadata":{},"source":["### Create the Direct Lake model based on the import/DQ semantic model\n","\n","Calculated columns are not migrated to the Direct Lake model as they are not supported in Direct Lake mode."]},{"cell_type":"code","execution_count":null,"id":"0a3616b5-566e-414e-a225-fb850d6418dc","metadata":{"jupyter":{"outputs_hidden":false,"source_hidden":false},"nteract":{"transient":{"deleting":false}}},"outputs":[],"source":["import time\n","labs.create_blank_semantic_model(dataset = new_dataset_name, workspace = new_dataset_workspace_name, overwrite=False)\n","\n","migration.migrate_calc_tables_to_lakehouse(\n"," dataset = dataset_name,\n"," new_dataset = new_dataset_name,\n"," workspace = workspace_name,\n"," new_dataset_workspace = new_dataset_workspace_name,\n"," lakehouse = lakehouse_name,\n"," lakehouse_workspace = lakehouse_workspace_name\n",")\n","migration.migrate_tables_columns_to_semantic_model(\n"," dataset = dataset_name,\n"," new_dataset = new_dataset_name,\n"," workspace = workspace_name,\n"," new_dataset_workspace = new_dataset_workspace_name,\n"," lakehouse = lakehouse_name,\n"," lakehouse_workspace = lakehouse_workspace_name\n",")\n","migration.migrate_calc_tables_to_semantic_model(\n"," dataset = dataset_name,\n"," new_dataset = new_dataset_name,\n"," workspace = workspace_name,\n"," new_dataset_workspace = new_dataset_workspace_name,\n"," lakehouse = lakehouse_name,\n"," lakehouse_workspace = lakehouse_workspace_name\n",")\n","migration.migrate_model_objects_to_semantic_model(\n"," dataset = dataset_name,\n"," new_dataset = new_dataset_name,\n"," workspace = workspace_name,\n"," new_dataset_workspace = new_dataset_workspace_name\n",")\n","migration.migrate_field_parameters(\n"," dataset = dataset_name,\n"," new_dataset = new_dataset_name,\n"," workspace = workspace_name,\n"," new_dataset_workspace = new_dataset_workspace_name\n",")\n","time.sleep(2)\n","labs.refresh_semantic_model(dataset = new_dataset_name, workspace = new_dataset_workspace_name)\n","migration.refresh_calc_tables(dataset = new_dataset_name, workspace = new_dataset_workspace_name)\n","labs.refresh_semantic_model(dataset = new_dataset_name, workspace = new_dataset_workspace_name)"]},{"cell_type":"markdown","id":"bb98bb13","metadata":{},"source":["### Show migrated/unmigrated objects"]},{"cell_type":"code","execution_count":null,"id":"5db2f22c","metadata":{},"outputs":[],"source":["migration.migration_validation(\n"," dataset = dataset_name,\n"," new_dataset = new_dataset_name, \n"," workspace = workspace_name, \n"," new_dataset_workspace = new_dataset_workspace_name\n",")"]},{"cell_type":"markdown","id":"fa244e9d-87c2-4a66-a7e0-be539a0ac7de","metadata":{"nteract":{"transient":{"deleting":false}}},"source":["### Rebind all reports using the old semantic model to the new Direct Lake semantic model"]},{"cell_type":"code","execution_count":null,"id":"d4e867cc","metadata":{},"outputs":[],"source":["rep.report_rebind_all(\n"," dataset = dataset_name,\n"," dataset_workspace = workspace_name,\n"," new_dataset = new_dataset_name,\n"," new_dataset_workpace = new_dataset_workspace_name,\n"," report_workspace = None\n",")"]},{"cell_type":"markdown","id":"3365d20d","metadata":{},"source":["### Rebind reports one-by-one (optional)"]},{"cell_type":"code","execution_count":null,"id":"056b7180-d7ac-492c-87e7-ac7d0e4bb929","metadata":{"jupyter":{"outputs_hidden":false,"source_hidden":false},"nteract":{"transient":{"deleting":false}}},"outputs":[],"source":["report_name = '' # Enter report name which you want to rebind to the new Direct Lake model\n","\n","rep.report_rebind(\n"," report = report_name,\n"," dataset = new_dataset_name,\n"," report_workspace=workspace_name,\n"," dataset_workspace = new_dataset_workspace_name)"]},{"cell_type":"markdown","id":"526f2327","metadata":{},"source":["### Show unsupported objects"]},{"cell_type":"code","execution_count":null,"id":"a47376d7","metadata":{},"outputs":[],"source":["dfT, dfC, dfR = directlake.show_unsupported_direct_lake_objects(dataset = dataset_name, workspace = workspace_name)\n","\n","print('Calculated Tables are not supported...')\n","display(dfT)\n","print(\"Learn more about Direct Lake limitations here: https://learn.microsoft.com/power-bi/enterprise/directlake-overview#known-issues-and-limitations\")\n","print('Calculated columns are not supported. Columns of binary data type are not supported.')\n","display(dfC)\n","print('Columns used for relationship must be of the same data type.')\n","display(dfR)"]},{"cell_type":"markdown","id":"ed08ba4c","metadata":{},"source":["### Schema check between semantic model tables/columns and lakehouse tables/columns\n","\n","This will list any tables/columns which are in the new semantic model but do not exist in the lakehouse"]},{"cell_type":"code","execution_count":null,"id":"03889ba4","metadata":{},"outputs":[],"source":["directlake.direct_lake_schema_compare(dataset = new_dataset_name, workspace = new_dataset_workspace_name)"]},{"cell_type":"markdown","id":"2229963b","metadata":{},"source":["### Show calculated tables which have been migrated to the Direct Lake semantic model as regular tables"]},{"cell_type":"code","execution_count":null,"id":"dd537d90","metadata":{},"outputs":[],"source":["directlake.list_direct_lake_model_calc_tables(dataset = new_dataset_name, workspace = new_dataset_workspace_name)"]}],"metadata":{"kernel_info":{"name":"synapse_pyspark"},"kernelspec":{"display_name":"Python 3","language":"python","name":"python3"},"language_info":{"name":"python","version":"3.12.3"},"microsoft":{"language":"python"},"nteract":{"version":"nteract-front-end@1.0.0"},"spark_compute":{"compute_id":"/trident/default"},"synapse_widget":{"state":{},"version":"0.1"},"widgets":{}},"nbformat":4,"nbformat_minor":5}
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "a024bb09",
+ "metadata": {},
+ "source": [
+ "### Watch thie video below to see a walkthrough of the Direct Lake Migration process\n",
+ "[](https://www.youtube.com/watch?v=gGIxMrTVyyI?t=495)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5c27dfd1-4fe0-4a97-92e6-ddf78889aa93",
+ "metadata": {
+ "nteract": {
+ "transient": {
+ "deleting": false
+ }
+ }
+ },
+ "source": [
+ "### Install the latest .whl package\n",
+ "\n",
+ "Check [here](https://pypi.org/project/semantic-link-labs/) to see the latest version."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d5cae9db-cef9-48a8-a351-9c5fcc99645c",
+ "metadata": {
+ "jupyter": {
+ "outputs_hidden": true,
+ "source_hidden": false
+ },
+ "nteract": {
+ "transient": {
+ "deleting": false
+ }
+ }
+ },
+ "outputs": [],
+ "source": [
+ "%pip install semantic-link-labs"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "969a29bf",
+ "metadata": {},
+ "source": [
+ "### Import the library and set initial parameters"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "29c923f8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import sempy_labs as labs\n",
+ "from sempy_labs import migration, directlake\n",
+ "import sempy_labs.report as rep\n",
+ "\n",
+ "dataset_name = '' #Enter the import/DQ semantic model name\n",
+ "workspace_name = None #Enter the workspace of the import/DQ semantic model. It set to none it will use the current workspace.\n",
+ "new_dataset_name = '' #Enter the new Direct Lake semantic model name\n",
+ "new_dataset_workspace_name = None #Enter the workspace where the Direct Lake model will be created. If set to None it will use the current workspace.\n",
+ "lakehouse_name = None #Enter the lakehouse to be used for the Direct Lake model. If set to None it will use the lakehouse attached to the notebook.\n",
+ "lakehouse_workspace_name = None #Enter the lakehouse workspace. If set to None it will use the new_dataset_workspace_name."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5a3fe6e8-b8aa-4447-812b-7931831e07fe",
+ "metadata": {
+ "nteract": {
+ "transient": {
+ "deleting": false
+ }
+ }
+ },
+ "source": [
+ "### Create the [Power Query Template](https://learn.microsoft.com/power-query/power-query-template) file\n",
+ "\n",
+ "This encapsulates all of the semantic model's Power Query logic into a single file."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cde43b47-4ecc-46ae-9125-9674819c7eab",
+ "metadata": {
+ "jupyter": {
+ "outputs_hidden": false,
+ "source_hidden": false
+ },
+ "nteract": {
+ "transient": {
+ "deleting": false
+ }
+ }
+ },
+ "outputs": [],
+ "source": [
+ "migration.create_pqt_file(dataset = dataset_name, workspace = workspace_name)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bf945d07-544c-4934-b7a6-cfdb90ca725e",
+ "metadata": {
+ "nteract": {
+ "transient": {
+ "deleting": false
+ }
+ }
+ },
+ "source": [
+ "### Import the Power Query Template to Dataflows Gen2\n",
+ "\n",
+ "- Open the [OneLake file explorer](https://www.microsoft.com/download/details.aspx?id=105222) and sync your files (right click -> Sync from OneLake)\n",
+ "\n",
+ "- Navigate to your lakehouse. From this window, create a new Dataflows Gen2 and import the Power Query Template file from OneLake (OneLake -> Workspace -> Lakehouse -> Files...), and publish the Dataflows Gen2.\n",
+ "\n",
+ "\n",
+ "Important! Make sure to create the Dataflows Gen2 from within the lakehouse window. That will ensure that all the tables automatically map to that lakehouse as the destination. Otherwise, you will have to manually map each table to its destination individually.\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9975db7d",
+ "metadata": {},
+ "source": [
+ "### Create the Direct Lake model based on the import/DQ semantic model\n",
+ "\n",
+ "Calculated columns are not migrated to the Direct Lake model as they are not supported in Direct Lake mode."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0a3616b5-566e-414e-a225-fb850d6418dc",
+ "metadata": {
+ "jupyter": {
+ "outputs_hidden": false,
+ "source_hidden": false
+ },
+ "nteract": {
+ "transient": {
+ "deleting": false
+ }
+ }
+ },
+ "outputs": [],
+ "source": [
+ "import time\n",
+ "labs.create_blank_semantic_model(dataset = new_dataset_name, workspace = new_dataset_workspace_name, overwrite=False)\n",
+ "\n",
+ "migration.migrate_calc_tables_to_lakehouse(\n",
+ " dataset=dataset_name,\n",
+ " new_dataset=new_dataset_name,\n",
+ " workspace=workspace_name,\n",
+ " new_dataset_workspace=new_dataset_workspace_name,\n",
+ " lakehouse=lakehouse_name,\n",
+ " lakehouse_workspace=lakehouse_workspace_name\n",
+ ")\n",
+ "migration.migrate_tables_columns_to_semantic_model(\n",
+ " dataset=dataset_name,\n",
+ " new_dataset=new_dataset_name,\n",
+ " workspace=workspace_name,\n",
+ " new_dataset_workspace=new_dataset_workspace_name,\n",
+ " lakehouse=lakehouse_name,\n",
+ " lakehouse_workspace=lakehouse_workspace_name\n",
+ ")\n",
+ "migration.migrate_calc_tables_to_semantic_model(\n",
+ " dataset=dataset_name,\n",
+ " new_dataset=new_dataset_name,\n",
+ " workspace=workspace_name,\n",
+ " new_dataset_workspace=new_dataset_workspace_name,\n",
+ " lakehouse=lakehouse_name,\n",
+ " lakehouse_workspace=lakehouse_workspace_name\n",
+ ")\n",
+ "migration.migrate_model_objects_to_semantic_model(\n",
+ " dataset=dataset_name,\n",
+ " new_dataset=new_dataset_name,\n",
+ " workspace=workspace_name,\n",
+ " new_dataset_workspace=new_dataset_workspace_name\n",
+ ")\n",
+ "migration.migrate_field_parameters(\n",
+ " dataset=dataset_name,\n",
+ " new_dataset=new_dataset_name,\n",
+ " workspace=workspace_name,\n",
+ " new_dataset_workspace=new_dataset_workspace_name\n",
+ ")\n",
+ "time.sleep(2)\n",
+ "labs.refresh_semantic_model(dataset=new_dataset_name, workspace=new_dataset_workspace_name)\n",
+ "migration.refresh_calc_tables(dataset=new_dataset_name, workspace=new_dataset_workspace_name)\n",
+ "labs.refresh_semantic_model(dataset=new_dataset_name, workspace=new_dataset_workspace_name)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bb98bb13",
+ "metadata": {},
+ "source": [
+ "### Show migrated/unmigrated objects"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5db2f22c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "migration.migration_validation(\n",
+ " dataset=dataset_name,\n",
+ " new_dataset=new_dataset_name, \n",
+ " workspace=workspace_name, \n",
+ " new_dataset_workspace=new_dataset_workspace_name\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fa244e9d-87c2-4a66-a7e0-be539a0ac7de",
+ "metadata": {
+ "nteract": {
+ "transient": {
+ "deleting": false
+ }
+ }
+ },
+ "source": [
+ "### Rebind all reports using the old semantic model to the new Direct Lake semantic model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d4e867cc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "rep.report_rebind_all(\n",
+ " dataset=dataset_name,\n",
+ " dataset_workspace=workspace_name,\n",
+ " new_dataset=new_dataset_name,\n",
+ " new_dataset_workpace=new_dataset_workspace_name,\n",
+ " report_workspace=None\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3365d20d",
+ "metadata": {},
+ "source": [
+ "### Rebind reports one-by-one (optional)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "056b7180-d7ac-492c-87e7-ac7d0e4bb929",
+ "metadata": {
+ "jupyter": {
+ "outputs_hidden": false,
+ "source_hidden": false
+ },
+ "nteract": {
+ "transient": {
+ "deleting": false
+ }
+ }
+ },
+ "outputs": [],
+ "source": [
+ "report_name = '' # Enter report name which you want to rebind to the new Direct Lake model\n",
+ "\n",
+ "rep.report_rebind(\n",
+ " report=report_name,\n",
+ " dataset=new_dataset_name,\n",
+ " report_workspace=workspace_name,\n",
+ " dataset_workspace=new_dataset_workspace_name)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "526f2327",
+ "metadata": {},
+ "source": [
+ "### Show unsupported objects"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a47376d7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "dfT, dfC, dfR = directlake.show_unsupported_direct_lake_objects(dataset = dataset_name, workspace = workspace_name)\n",
+ "\n",
+ "print('Calculated Tables are not supported...')\n",
+ "display(dfT)\n",
+ "print(\"Learn more about Direct Lake limitations here: https://learn.microsoft.com/power-bi/enterprise/directlake-overview#known-issues-and-limitations\")\n",
+ "print('Calculated columns are not supported. Columns of binary data type are not supported.')\n",
+ "display(dfC)\n",
+ "print('Columns used for relationship must be of the same data type.')\n",
+ "display(dfR)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ed08ba4c",
+ "metadata": {},
+ "source": [
+ "### Schema check between semantic model tables/columns and lakehouse tables/columns\n",
+ "\n",
+ "This will list any tables/columns which are in the new semantic model but do not exist in the lakehouse"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "03889ba4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "directlake.direct_lake_schema_compare(dataset=new_dataset_name, workspace=new_dataset_workspace_name)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2229963b",
+ "metadata": {},
+ "source": [
+ "### Show calculated tables which have been migrated to the Direct Lake semantic model as regular tables"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "dd537d90",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "directlake.list_direct_lake_model_calc_tables(dataset=new_dataset_name, workspace=new_dataset_workspace_name)"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernel_info": {
+ "name": "synapse_pyspark"
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "name": "python",
+ "version": "3.12.3"
+ },
+ "microsoft": {
+ "language": "python"
+ },
+ "nteract": {
+ "version": "nteract-front-end@1.0.0"
+ },
+ "spark_compute": {
+ "compute_id": "/trident/default"
+ },
+ "synapse_widget": {
+ "state": {},
+ "version": "0.1"
+ },
+ "widgets": {}
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/notebooks/Model Optimization.ipynb b/notebooks/Model Optimization.ipynb
index 45ab4d00..d3fa9211 100644
--- a/notebooks/Model Optimization.ipynb
+++ b/notebooks/Model Optimization.ipynb
@@ -1 +1,444 @@
-{"cells":[{"cell_type":"markdown","id":"5c27dfd1-4fe0-4a97-92e6-ddf78889aa93","metadata":{"nteract":{"transient":{"deleting":false}}},"source":["### Install the latest .whl package\n","\n","Check [here](https://pypi.org/project/semantic-link-labs/) to see the latest version."]},{"cell_type":"code","execution_count":null,"id":"d5cae9db-cef9-48a8-a351-9c5fcc99645c","metadata":{"jupyter":{"outputs_hidden":true,"source_hidden":false},"nteract":{"transient":{"deleting":false}}},"outputs":[],"source":["%pip install semantic-link-labs"]},{"cell_type":"markdown","id":"cd8de5a0","metadata":{},"source":["### Import the library"]},{"cell_type":"code","execution_count":null,"id":"5cc6eedf","metadata":{},"outputs":[],"source":["import sempy_labs as labs\n","from sempy_labs import lakehouse as lake\n","from sempy_labs import directlake\n","import sempy_labs.report as rep\n","\n","dataset_name = ''\n","workspace_name = None"]},{"cell_type":"markdown","id":"5a3fe6e8-b8aa-4447-812b-7931831e07fe","metadata":{"nteract":{"transient":{"deleting":false}}},"source":["### Vertipaq Analyzer"]},{"cell_type":"code","execution_count":null,"id":"cde43b47-4ecc-46ae-9125-9674819c7eab","metadata":{"jupyter":{"outputs_hidden":false,"source_hidden":false},"nteract":{"transient":{"deleting":false}}},"outputs":[],"source":["labs.vertipaq_analyzer(dataset = dataset_name, workspace = workspace_name)"]},{"cell_type":"markdown","id":"419a348f","metadata":{},"source":["Export the Vertipaq Analyzer results to a .zip file in your lakehouse"]},{"cell_type":"code","execution_count":null,"id":"8aa239b3","metadata":{},"outputs":[],"source":["labs.vertipaq_analyzer(dataset = dataset_name, workspace = workspace_name, export = 'zip')"]},{"cell_type":"markdown","id":"2dce0f4f","metadata":{},"source":["Export the Vertipaq Analyzer results to append to delta tables in your lakehouse."]},{"cell_type":"code","execution_count":null,"id":"aef93fc8","metadata":{},"outputs":[],"source":["labs.vertipaq_analyzer(dataset = dataset_name, workspace = workspace_name, export = 'table')"]},{"cell_type":"markdown","id":"1c62a802","metadata":{},"source":["Visualize the contents of an exported Vertipaq Analzyer .zip file."]},{"cell_type":"code","execution_count":null,"id":"9e349954","metadata":{},"outputs":[],"source":["labs.import_vertipaq_analyzer(folder_path = '', file_name = '')"]},{"cell_type":"markdown","id":"456ce0ff","metadata":{},"source":["### Best Practice Analzyer\n","\n","This runs the [standard rules](https://github.com/microsoft/Analysis-Services/tree/master/BestPracticeRules) for semantic models posted on Microsoft's GitHub."]},{"cell_type":"code","execution_count":null,"id":"0a3616b5-566e-414e-a225-fb850d6418dc","metadata":{"jupyter":{"outputs_hidden":false,"source_hidden":false},"nteract":{"transient":{"deleting":false}}},"outputs":[],"source":["labs.run_model_bpa(dataset = dataset_name, workspace = workspace_name)"]},{"cell_type":"markdown","id":"6fb32a58","metadata":{},"source":["This runs the Best Practice Analyzer and exports the results to the 'modelbparesults' delta table in your Fabric lakehouse."]},{"cell_type":"code","execution_count":null,"id":"677851c3","metadata":{},"outputs":[],"source":["labs.run_model_bpa(dataset = dataset_name, workspace = workspace_name, export = True)"]},{"cell_type":"markdown","id":"64968a31","metadata":{},"source":["This runs the Best Practice Analyzer with the rules translated into Italian."]},{"cell_type":"code","execution_count":null,"id":"3c7d89e2","metadata":{},"outputs":[],"source":["labs.run_model_bpa(dataset = dataset_name, workspace = workspace_name, language = 'it-IT')"]},{"cell_type":"markdown","id":"255c30bb","metadata":{},"source":["\n","Note: For analyzing model BPA results at scale, see the Best Practice Analyzer Report notebook (link below).\n","
\n","\n","[Best Practice Analyzer Notebook](https://github.com/microsoft/semantic-link-labs/blob/main/notebooks/Best%20Practice%20Analyzer%20Report.ipynb)"]},{"cell_type":"markdown","id":"bab18a61","metadata":{},"source":["### Run BPA using your own best practice rules"]},{"cell_type":"code","execution_count":null,"id":"59b89387","metadata":{},"outputs":[],"source":["import sempy\n","sempy.fabric._client._utils._init_analysis_services()\n","import Microsoft.AnalysisServices.Tabular as TOM\n","import pandas as pd\n","\n","dataset_name = ''\n","workspace_name = ''\n","\n","rules = pd.DataFrame(\n"," [\n"," (\n"," \"Performance\",\n"," \"Table\",\n"," \"Warning\",\n"," \"Rule name...\",\n"," lambda obj, tom: tom.is_calculated_table(table_name=obj.Name),\n"," 'Rule description...',\n"," '',\n"," ),\n"," (\n"," \"Performance\",\n"," \"Column\",\n"," \"Warning\",\n"," \"Do not use floating point data types\",\n"," lambda obj, tom: obj.DataType == TOM.DataType.Double,\n"," 'The \"Double\" floating point data type should be avoided, as it can result in unpredictable roundoff errors and decreased performance in certain scenarios. Use \"Int64\" or \"Decimal\" where appropriate (but note that \"Decimal\" is limited to 4 digits after the decimal sign).',\n"," )\n"," ],\n"," columns=[\n"," \"Category\",\n"," \"Scope\",\n"," \"Severity\",\n"," \"Rule Name\",\n"," \"Expression\",\n"," \"Description\",\n"," \"URL\",\n"," ],\n",")\n","\n","labs.run_model_bpa(dataset=dataset_name, workspace=workspace_name, rules=rules)"]},{"cell_type":"markdown","id":"8126a1a1","metadata":{},"source":["### Direct Lake\n","\n","Check if any lakehouse tables will hit the [Direct Lake guardrails](https://learn.microsoft.com/power-bi/enterprise/directlake-overview#fallback)."]},{"cell_type":"code","execution_count":null,"id":"e7397b15","metadata":{},"outputs":[],"source":["lake.get_lakehouse_tables(lakehouse = None, workspace = None, extended = True, count_rows = False)"]},{"cell_type":"code","execution_count":null,"id":"b30074cf","metadata":{},"outputs":[],"source":["lake.get_lakehouse_tables(lakehouse = None, workspace = None, extended = True, count_rows = False, export = True)"]},{"cell_type":"markdown","id":"99b84f2b","metadata":{},"source":["Check if any tables in a Direct Lake semantic model will fall back to DirectQuery."]},{"cell_type":"code","execution_count":null,"id":"f837be58","metadata":{},"outputs":[],"source":["directlake.check_fallback_reason(dataset = dataset_name, workspace = workspace_name)"]},{"cell_type":"markdown","id":"8f6df93e","metadata":{},"source":["### [OPTIMIZE](https://docs.delta.io/latest/optimizations-oss.html) your lakehouse delta tables."]},{"cell_type":"code","execution_count":null,"id":"e0262c9e","metadata":{},"outputs":[],"source":["lake.optimize_lakehouse_tables(tables = ['', ''], lakehouse = None, workspace = None)"]},{"cell_type":"markdown","id":"0091d6a0","metadata":{},"source":["Refresh/reframe your Direct Lake semantic model and restore the columns which were in memory prior to the refresh."]},{"cell_type":"code","execution_count":null,"id":"77eef082","metadata":{},"outputs":[],"source":["directlake.warm_direct_lake_cache_isresident(dataset = dataset_name, workspace = workspace_name)"]},{"cell_type":"markdown","id":"dae1a210","metadata":{},"source":["Ensure a warm cache for your users by putting the columns of a Direct Lake semantic model into memory based on the contents of a [perspective](https://learn.microsoft.com/analysis-services/tabular-models/perspectives-ssas-tabular?view=asallproducts-allversions).\n","\n","Perspectives can be created either in [Tabular Editor 3](https://github.com/TabularEditor/TabularEditor3/releases/latest) or in [Tabular Editor 2](https://github.com/TabularEditor/TabularEditor/releases/latest) using the [Perspective Editor](https://www.elegantbi.com/post/perspectiveeditor)."]},{"cell_type":"code","execution_count":null,"id":"43297001","metadata":{},"outputs":[],"source":["directlake.warm_direct_lake_cache_perspective(dataset = dataset_name, workspace = workspace_name, perspective = '', add_dependencies = True)"]}],"metadata":{"kernel_info":{"name":"synapse_pyspark"},"kernelspec":{"display_name":"Synapse PySpark","language":"Python","name":"synapse_pyspark"},"language_info":{"name":"python"},"microsoft":{"language":"python"},"nteract":{"version":"nteract-front-end@1.0.0"},"spark_compute":{"compute_id":"/trident/default"},"synapse_widget":{"state":{},"version":"0.1"},"widgets":{}},"nbformat":4,"nbformat_minor":5}
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "5c27dfd1-4fe0-4a97-92e6-ddf78889aa93",
+ "metadata": {
+ "nteract": {
+ "transient": {
+ "deleting": false
+ }
+ }
+ },
+ "source": [
+ "### Install the latest .whl package\n",
+ "\n",
+ "Check [here](https://pypi.org/project/semantic-link-labs/) to see the latest version."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d5cae9db-cef9-48a8-a351-9c5fcc99645c",
+ "metadata": {
+ "jupyter": {
+ "outputs_hidden": true,
+ "source_hidden": false
+ },
+ "nteract": {
+ "transient": {
+ "deleting": false
+ }
+ }
+ },
+ "outputs": [],
+ "source": [
+ "%pip install semantic-link-labs"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cd8de5a0",
+ "metadata": {},
+ "source": [
+ "### Import the library"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5cc6eedf",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import sempy_labs as labs\n",
+ "from sempy_labs import lakehouse as lake\n",
+ "from sempy_labs import directlake\n",
+ "import sempy_labs.report as rep\n",
+ "\n",
+ "dataset_name = ''\n",
+ "workspace_name = None"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5a3fe6e8-b8aa-4447-812b-7931831e07fe",
+ "metadata": {
+ "nteract": {
+ "transient": {
+ "deleting": false
+ }
+ }
+ },
+ "source": [
+ "### Vertipaq Analyzer \n",
+ "\n",
+ "[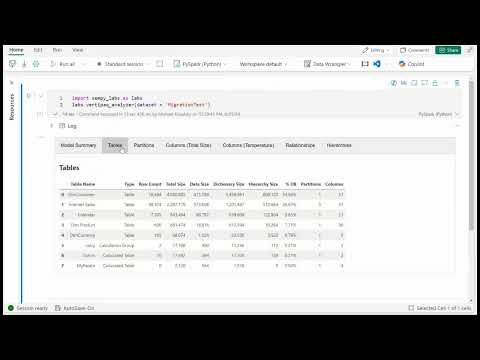](https://www.youtube.com/watch?v=RnrwUqg2-VI)\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cde43b47-4ecc-46ae-9125-9674819c7eab",
+ "metadata": {
+ "jupyter": {
+ "outputs_hidden": false,
+ "source_hidden": false
+ },
+ "nteract": {
+ "transient": {
+ "deleting": false
+ }
+ }
+ },
+ "outputs": [],
+ "source": [
+ "labs.vertipaq_analyzer(dataset=dataset_name, workspace=workspace_name)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "419a348f",
+ "metadata": {},
+ "source": [
+ "Export the Vertipaq Analyzer results to a .zip file in your lakehouse"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8aa239b3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "labs.vertipaq_analyzer(dataset=dataset_name, workspace=workspace_name, export='zip')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2dce0f4f",
+ "metadata": {},
+ "source": [
+ "Export the Vertipaq Analyzer results to append to delta tables in your lakehouse."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "aef93fc8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "labs.vertipaq_analyzer(dataset=dataset_name, workspace=workspace_name, export='table')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1c62a802",
+ "metadata": {},
+ "source": [
+ "Visualize the contents of an exported Vertipaq Analzyer .zip file."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9e349954",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "labs.import_vertipaq_analyzer(folder_path='', file_name='')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "456ce0ff",
+ "metadata": {},
+ "source": [
+ "### Best Practice Analzyer\n",
+ "\n",
+ "[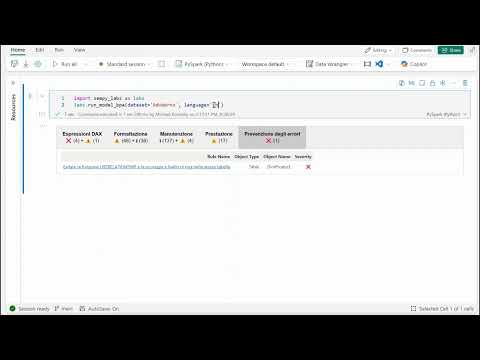](https://www.youtube.com/watch?v=095avwDn4Hk)\n",
+ "\n",
+ "This runs the [standard rules](https://github.com/microsoft/Analysis-Services/tree/master/BestPracticeRules) for semantic models posted on Microsoft's GitHub."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0a3616b5-566e-414e-a225-fb850d6418dc",
+ "metadata": {
+ "jupyter": {
+ "outputs_hidden": false,
+ "source_hidden": false
+ },
+ "nteract": {
+ "transient": {
+ "deleting": false
+ }
+ }
+ },
+ "outputs": [],
+ "source": [
+ "labs.run_model_bpa(dataset=dataset_name, workspace=workspace_name)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6fb32a58",
+ "metadata": {},
+ "source": [
+ "This runs the Best Practice Analyzer and exports the results to the 'modelbparesults' delta table in your Fabric lakehouse."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "677851c3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "labs.run_model_bpa(dataset=dataset_name, workspace=workspace_name, export=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "64968a31",
+ "metadata": {},
+ "source": [
+ "This runs the Best Practice Analyzer with the rules translated into Italian (can enter any language in the 'language' parameter)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3c7d89e2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "labs.run_model_bpa(dataset=dataset_name, workspace=workspace_name, language='italian')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "255c30bb",
+ "metadata": {},
+ "source": [
+ "\n",
+ "Note: For analyzing model BPA results at scale, see the Best Practice Analyzer Report notebook (link below).\n",
+ "
\n",
+ "\n",
+ "[Best Practice Analyzer Report](https://github.com/microsoft/semantic-link-labs/blob/main/notebooks/Best%20Practice%20Analyzer%20Report.ipynb)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bab18a61",
+ "metadata": {},
+ "source": [
+ "### Run BPA using your own best practice rules"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "59b89387",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import sempy\n",
+ "sempy.fabric._client._utils._init_analysis_services()\n",
+ "import Microsoft.AnalysisServices.Tabular as TOM\n",
+ "import pandas as pd\n",
+ "\n",
+ "dataset_name = ''\n",
+ "workspace_name = ''\n",
+ "\n",
+ "rules = pd.DataFrame(\n",
+ " [\n",
+ " (\n",
+ " \"Performance\",\n",
+ " \"Table\",\n",
+ " \"Warning\",\n",
+ " \"Rule name...\",\n",
+ " lambda obj, tom: tom.is_calculated_table(table_name=obj.Name),\n",
+ " 'Rule description...',\n",
+ " '',\n",
+ " ),\n",
+ " (\n",
+ " \"Performance\",\n",
+ " \"Column\",\n",
+ " \"Warning\",\n",
+ " \"Do not use floating point data types\",\n",
+ " lambda obj, tom: obj.DataType == TOM.DataType.Double,\n",
+ " 'The \"Double\" floating point data type should be avoided, as it can result in unpredictable roundoff errors and decreased performance in certain scenarios. Use \"Int64\" or \"Decimal\" where appropriate (but note that \"Decimal\" is limited to 4 digits after the decimal sign).',\n",
+ " )\n",
+ " ],\n",
+ " columns=[\n",
+ " \"Category\",\n",
+ " \"Scope\",\n",
+ " \"Severity\",\n",
+ " \"Rule Name\",\n",
+ " \"Expression\",\n",
+ " \"Description\",\n",
+ " \"URL\",\n",
+ " ],\n",
+ ")\n",
+ "\n",
+ "labs.run_model_bpa(dataset=dataset_name, workspace=workspace_name, rules=rules)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8111313f",
+ "metadata": {},
+ "source": [
+ "### Translate a semantic model's metadata\n",
+ "\n",
+ "[](https://www.youtube.com/watch?v=5hmeuZGDAws)\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "af687705",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "labs.translate_semantic_model(dataset=dataset_name, workspace=workspace_name, languages=['italian', 'japanese', 'hindi'], exclude_characters='_')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8126a1a1",
+ "metadata": {},
+ "source": [
+ "### Direct Lake\n",
+ "\n",
+ "Check if any lakehouse tables will hit the [Direct Lake guardrails](https://learn.microsoft.com/power-bi/enterprise/directlake-overview#fallback)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e7397b15",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "lake.get_lakehouse_tables(lakehouse=None, workspace=None, extended=True, count_rows=False)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b30074cf",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "lake.get_lakehouse_tables(lakehouse=None, workspace=None, extended=True, count_rows=False, export=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "99b84f2b",
+ "metadata": {},
+ "source": [
+ "Check if any tables in a Direct Lake semantic model will fall back to DirectQuery."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f837be58",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "directlake.check_fallback_reason(dataset=dataset_name, workspace=workspace_name)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8f6df93e",
+ "metadata": {},
+ "source": [
+ "### [OPTIMIZE](https://docs.delta.io/latest/optimizations-oss.html) your lakehouse delta tables."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e0262c9e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "lake.optimize_lakehouse_tables(tables=['', ''], lakehouse=None, workspace=None)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0091d6a0",
+ "metadata": {},
+ "source": [
+ "Refresh/reframe your Direct Lake semantic model and restore the columns which were in memory prior to the refresh."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "77eef082",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "directlake.warm_direct_lake_cache_isresident(dataset=dataset_name, workspace=workspace_name)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dae1a210",
+ "metadata": {},
+ "source": [
+ "Ensure a warm cache for your users by putting the columns of a Direct Lake semantic model into memory based on the contents of a [perspective](https://learn.microsoft.com/analysis-services/tabular-models/perspectives-ssas-tabular?view=asallproducts-allversions).\n",
+ "\n",
+ "Perspectives can be created either in [Tabular Editor 3](https://github.com/TabularEditor/TabularEditor3/releases/latest) or in [Tabular Editor 2](https://github.com/TabularEditor/TabularEditor/releases/latest) using the [Perspective Editor](https://www.elegantbi.com/post/perspectiveeditor)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "43297001",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "directlake.warm_direct_lake_cache_perspective(dataset=dataset_name, workspace=workspace_name, perspective='', add_dependencies=True)"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernel_info": {
+ "name": "synapse_pyspark"
+ },
+ "kernelspec": {
+ "display_name": "Synapse PySpark",
+ "language": "Python",
+ "name": "synapse_pyspark"
+ },
+ "language_info": {
+ "name": "python"
+ },
+ "microsoft": {
+ "language": "python"
+ },
+ "nteract": {
+ "version": "nteract-front-end@1.0.0"
+ },
+ "spark_compute": {
+ "compute_id": "/trident/default"
+ },
+ "synapse_widget": {
+ "state": {},
+ "version": "0.1"
+ },
+ "widgets": {}
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/notebooks/Query Scale Out.ipynb b/notebooks/Query Scale Out.ipynb
index e2690bd9..78e2aec5 100644
--- a/notebooks/Query Scale Out.ipynb
+++ b/notebooks/Query Scale Out.ipynb
@@ -1 +1,226 @@
-{"cells":[{"cell_type":"markdown","id":"5c27dfd1-4fe0-4a97-92e6-ddf78889aa93","metadata":{"nteract":{"transient":{"deleting":false}}},"source":["### Install the latest .whl package\n","\n","Check [here](https://pypi.org/project/semantic-link-labs/) to see the latest version."]},{"cell_type":"code","execution_count":null,"id":"d5cae9db-cef9-48a8-a351-9c5fcc99645c","metadata":{"jupyter":{"outputs_hidden":true,"source_hidden":false},"nteract":{"transient":{"deleting":false}}},"outputs":[],"source":["%pip install semantic-link-labs"]},{"cell_type":"markdown","id":"b195eae8","metadata":{},"source":["### Import the library and set the initial parameters"]},{"cell_type":"code","execution_count":null,"id":"1344e286","metadata":{},"outputs":[],"source":["import sempy_labs as labs\n","dataset = '' # Enter your dataset name\n","workspace = None # Enter your workspace name (if set to None it will use the workspace in which the notebook is running)"]},{"cell_type":"markdown","id":"5a3fe6e8-b8aa-4447-812b-7931831e07fe","metadata":{"nteract":{"transient":{"deleting":false}}},"source":["### View [Query Scale Out](https://learn.microsoft.com/power-bi/enterprise/service-premium-scale-out) (QSO) settings"]},{"cell_type":"code","execution_count":null,"id":"9e349954","metadata":{},"outputs":[],"source":["labs.list_qso_settings(dataset = dataset, workspace = workspace )"]},{"cell_type":"markdown","id":"b0717cbb","metadata":{},"source":["### [Configure Query Scale Out](https://learn.microsoft.com/power-bi/enterprise/service-premium-scale-out-configure)\n","Setting 'auto_sync' to True will ensure that the semantic model automatically syncs read-only replicas. Setting this to False will necessitate syncing the replicas (i.e. via the qso_sync function).\n","\n","The 'max_read_only_replicas' is the maximum number of read-only replicas for the semantic model (0-64, -1 for automatic number of replicas).\n"]},{"cell_type":"code","execution_count":null,"id":"ec37dd14","metadata":{},"outputs":[],"source":["labs.set_qso(dataset = dataset, auto_sync = False, max_read_only_replicas = -1, workspace = workspace)"]},{"cell_type":"markdown","id":"5d6beadd","metadata":{},"source":["### Sync Query Scale Out replicas"]},{"cell_type":"code","execution_count":null,"id":"7ca10963","metadata":{},"outputs":[],"source":["labs.qso_sync(dataset = dataset, workspace = workspace)"]},{"cell_type":"markdown","id":"719f428f","metadata":{},"source":["### Check Query Scale Out Sync Status"]},{"cell_type":"code","execution_count":null,"id":"db6f197c","metadata":{},"outputs":[],"source":["dfA, dfB = labs.qso_sync_status(dataset = dataset, workspace = workspace)\n","display(dfA)\n","display(dfB)"]},{"cell_type":"markdown","id":"e92cdf34","metadata":{},"source":["### Disable Query Scale Out"]},{"cell_type":"code","execution_count":null,"id":"0624d649","metadata":{},"outputs":[],"source":["labs.disable_qso(dataset = dataset, workspace = workspace)"]},{"cell_type":"markdown","id":"786d89bc","metadata":{},"source":["### Enable large semantic model format"]},{"cell_type":"code","execution_count":null,"id":"d521b228","metadata":{},"outputs":[],"source":["labs.set_semantic_model_storage_format(dataset = dataset, storage_format = 'Large', workspace = workspace)"]},{"cell_type":"markdown","id":"e90c20e9","metadata":{},"source":["### Disable large semantic model format"]},{"cell_type":"code","execution_count":null,"id":"433220b2","metadata":{},"outputs":[],"source":["labs.set_semantic_model_storage_format(dataset = dataset, storage_format = 'Small', workspace = workspace)"]}],"metadata":{"kernel_info":{"name":"synapse_pyspark"},"kernelspec":{"display_name":"Synapse PySpark","language":"Python","name":"synapse_pyspark"},"language_info":{"name":"python"},"microsoft":{"language":"python"},"nteract":{"version":"nteract-front-end@1.0.0"},"spark_compute":{"compute_id":"/trident/default"},"synapse_widget":{"state":{},"version":"0.1"},"widgets":{}},"nbformat":4,"nbformat_minor":5}
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "5c27dfd1-4fe0-4a97-92e6-ddf78889aa93",
+ "metadata": {
+ "nteract": {
+ "transient": {
+ "deleting": false
+ }
+ }
+ },
+ "source": [
+ "### Install the latest .whl package\n",
+ "\n",
+ "Check [here](https://pypi.org/project/semantic-link-labs/) to see the latest version."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d5cae9db-cef9-48a8-a351-9c5fcc99645c",
+ "metadata": {
+ "jupyter": {
+ "outputs_hidden": true,
+ "source_hidden": false
+ },
+ "nteract": {
+ "transient": {
+ "deleting": false
+ }
+ }
+ },
+ "outputs": [],
+ "source": [
+ "%pip install semantic-link-labs"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b195eae8",
+ "metadata": {},
+ "source": [
+ "### Import the library and set the initial parameters"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1344e286",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import sempy_labs as labs\n",
+ "dataset = '' # Enter your dataset name\n",
+ "workspace = None # Enter your workspace name (if set to None it will use the workspace in which the notebook is running)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5a3fe6e8-b8aa-4447-812b-7931831e07fe",
+ "metadata": {
+ "nteract": {
+ "transient": {
+ "deleting": false
+ }
+ }
+ },
+ "source": [
+ "### View [Query Scale Out](https://learn.microsoft.com/power-bi/enterprise/service-premium-scale-out) (QSO) settings"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9e349954",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "labs.list_qso_settings(dataset=dataset, workspace=workspace )"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b0717cbb",
+ "metadata": {},
+ "source": [
+ "### [Configure Query Scale Out](https://learn.microsoft.com/power-bi/enterprise/service-premium-scale-out-configure)\n",
+ "Setting 'auto_sync' to True will ensure that the semantic model automatically syncs read-only replicas. Setting this to False will necessitate syncing the replicas (i.e. via the qso_sync function).\n",
+ "\n",
+ "The 'max_read_only_replicas' is the maximum number of read-only replicas for the semantic model (0-64, -1 for automatic number of replicas).\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ec37dd14",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "labs.set_qso(dataset=dataset, auto_sync=False, max_read_only_replicas=-1, workspace=workspace)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5d6beadd",
+ "metadata": {},
+ "source": [
+ "### Sync Query Scale Out replicas"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7ca10963",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "labs.qso_sync(dataset=dataset, workspace=workspace)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "719f428f",
+ "metadata": {},
+ "source": [
+ "### Check Query Scale Out Sync Status"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "db6f197c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "dfA, dfB = labs.qso_sync_status(dataset=dataset, workspace=workspace)\n",
+ "display(dfA)\n",
+ "display(dfB)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e92cdf34",
+ "metadata": {},
+ "source": [
+ "### Disable Query Scale Out"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0624d649",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "labs.disable_qso(dataset=dataset, workspace=workspace)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "786d89bc",
+ "metadata": {},
+ "source": [
+ "### Enable large semantic model format"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d521b228",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "labs.set_semantic_model_storage_format(dataset=dataset, storage_format='Large', workspace=workspace)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e90c20e9",
+ "metadata": {},
+ "source": [
+ "### Disable large semantic model format"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "433220b2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "labs.set_semantic_model_storage_format(dataset=dataset, storage_format='Small', workspace=workspace)"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernel_info": {
+ "name": "synapse_pyspark"
+ },
+ "kernelspec": {
+ "display_name": "Synapse PySpark",
+ "language": "Python",
+ "name": "synapse_pyspark"
+ },
+ "language_info": {
+ "name": "python"
+ },
+ "microsoft": {
+ "language": "python"
+ },
+ "nteract": {
+ "version": "nteract-front-end@1.0.0"
+ },
+ "spark_compute": {
+ "compute_id": "/trident/default"
+ },
+ "synapse_widget": {
+ "state": {},
+ "version": "0.1"
+ },
+ "widgets": {}
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/src/sempy_labs/_model_bpa_bulk.py b/src/sempy_labs/_model_bpa_bulk.py
index 803ad5af..8b66e4e2 100644
--- a/src/sempy_labs/_model_bpa_bulk.py
+++ b/src/sempy_labs/_model_bpa_bulk.py
@@ -33,8 +33,6 @@ def run_model_bpa_bulk(
Parameters
----------
- dataset : str
- Name of the semantic model.
rules : pandas.DataFrame, default=None
A pandas dataframe containing rules to be evaluated. Based on the format of the dataframe produced by the model_bpa_rules function.
extended : bool, default=False
diff --git a/src/sempy_labs/_refresh_semantic_model.py b/src/sempy_labs/_refresh_semantic_model.py
index 3183e41f..bc2e5180 100644
--- a/src/sempy_labs/_refresh_semantic_model.py
+++ b/src/sempy_labs/_refresh_semantic_model.py
@@ -226,7 +226,7 @@ def display_trace_logs(trace, partition_map, widget, title, stop=False):
)
print(
- f"{icons.green_dot} Refresh of the '{dataset}' semantic model within the '{workspace}' workspace is complete."
+ f"{icons.green_dot} Refresh '{refresh_type}' of the '{dataset}' semantic model within the '{workspace}' workspace is complete."
)
return final_df
@@ -247,7 +247,7 @@ def display_trace_logs(trace, partition_map, widget, title, stop=False):
time.sleep(3)
print(
- f"{icons.green_dot} Refresh of the '{dataset}' semantic model within the '{workspace}' workspace is complete."
+ f"{icons.green_dot} Refresh '{refresh_type}' of the '{dataset}' semantic model within the '{workspace}' workspace is complete."
)
final_output = refresh_and_trace_dataset(
diff --git a/src/sempy_labs/report/_export_report.py b/src/sempy_labs/report/_export_report.py
new file mode 100644
index 00000000..5e175431
--- /dev/null
+++ b/src/sempy_labs/report/_export_report.py
@@ -0,0 +1,73 @@
+import sempy.fabric as fabric
+import sempy_labs._icons as icons
+from typing import Optional
+from sempy_labs._helper_functions import (
+ resolve_workspace_name_and_id,
+ resolve_lakehouse_name,
+)
+from sempy_labs.lakehouse._lakehouse import lakehouse_attached
+from sempy.fabric.exceptions import FabricHTTPException
+
+
+def export_report(
+ report: str,
+ file_name: Optional[str] = None,
+ download_type: str = "LiveConnect",
+ workspace: Optional[str] = None,
+):
+ """
+ Exports the specified report from the specified workspace to a Power BI .pbix file.
+
+ This is a wrapper function for the following API: `Reports - Export Report In Group `.
+
+ Parameters
+ ----------
+ report: str
+ Name of the report.
+ file_name : str, default=None
+ Name of the .pbix file to be saved.
+ Defaults to None which resolves to the name of the report.
+ download_type : str, default="LiveConnect"
+ The type of download. Valid values are "LiveConnect" and "IncludeModel".
+ workspace : str, default=None
+ The Fabric workspace name.
+ Defaults to None which resolves to the workspace of the attached lakehouse
+ or if no lakehouse attached, resolves to the workspace of the notebook.
+ """
+
+ if not lakehouse_attached():
+ raise ValueError(
+ f"{icons.red_dot} A lakehouse must be attached to the notebook."
+ )
+
+ lakehouse_id = fabric.get_lakehouse_id()
+ workspace_name = fabric.resolve_workspace_name()
+ lakehouse_name = resolve_lakehouse_name(lakehouse_id=lakehouse_id, workspace=workspace_name)
+
+ download_types = ["LiveConnect", "IncludeModel"]
+ if download_type not in download_types:
+ raise ValueError(
+ f"{icons.red_dot} Invalid download_type parameter. Valid options: {download_types}."
+ )
+
+ file_name = file_name or report
+ (workspace, workspace_id) = resolve_workspace_name_and_id(workspace)
+ report_id = fabric.resolve_item_id(
+ item_name=report, type="Report", workspace=workspace
+ )
+
+ client = fabric.PowerBIRestClient()
+ response = client.get(
+ f"/v1.0/myorg/groups/{workspace_id}/reports/{report_id}/Export?downloadType={download_type}"
+ )
+
+ if response.status_code != 200:
+ raise FabricHTTPException(response)
+
+ # Save file to the attached lakehouse
+ with open(f"/lakehouse/default/Files/{file_name}.pbix", "wb") as file:
+ file.write(response.content)
+
+ print(
+ f"{icons.green_dot} The '{report}' report within the '{workspace}' workspace has been exported as the '{file_name}' file in the '{lakehouse_name}' lakehouse within the '{workspace_name} workspace."
+ )