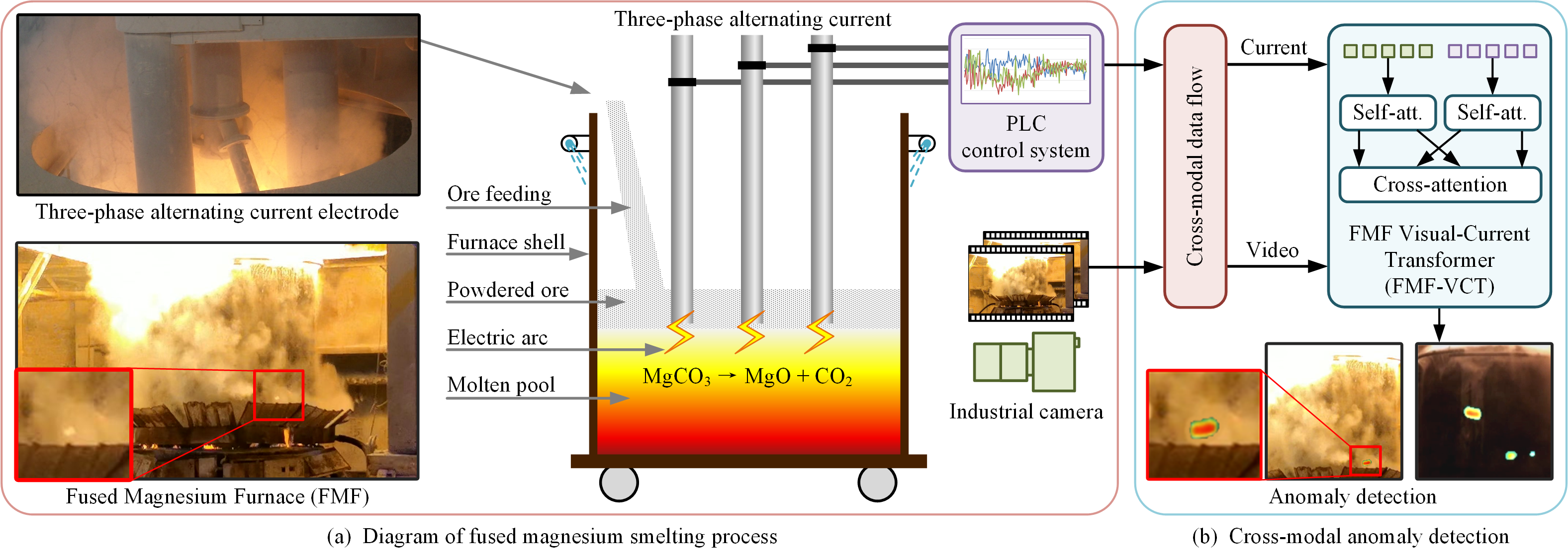
This is a cross-modal benchmark for the fused magnesium smelting process. The benchmark contains a total of 3 hours of synchronously acquired videos and three-phase alternating current data from different production batches.
-
12/08/2025: The Baidu Disk dataset link has been updated.
-
03/04/2025: Our dataset, featuring diverse sampling rates, is now available for download.
-
02/13/2025: Our code is now available.
-
12/16/2024: Our code is cooming soon.
-
11/25/2024: Our dataset with pixel-level annotations is now available for download. You can access it via:
Google Drive: https://drive.google.com/file/d/12vQ_CHqKQ5TOK6i9whKO39OZO4Nssz_e/view?usp=sharing
Baidu Disk: https://pan.baidu.com/s/1es0GzxQnFLiJigsIs5wB4A?pwd=5nz5 (Fetch Code: 5nz5)
Baidu Disk: https://pan.baidu.com/s/1fh6xiVDn1kxJiM17eUZEIQ?pwd=ebu3 (Fetch Code: ebu3) Note: Synchronous acquisition with different sampling rates.
-
11/01/2024: We are in the process of preparing the datasets, which are currently not very convenient for research usage. If you would like to access the dataset in advance, please feel free to contact us: wugc\at mail\dot neu\dot edu\dot cn.
This dataset includes three sets of data stored in .mat format, comprising
-
video: A 4D tensor of shape(height, width, RGB channel, N)representing the 3D video modality. Here,Ndenotes the number of frames. -
current: A 2D array of shape(phase channel, N)representing the 1D three-phase alternating current modality. -
label: A 3D tensor of shape(height, width, N)representing pixel-level normal (0) and abnormal (1) masks. You can convert these masks to class-level labels using the formula:class_label = single(sum(label, [1, 2]) > 0.5); # Matlab code
-
train_test_index: A 1D array of shape(1, N)indicating the train-test split. A value of0represents a training example, while1indicates a test example.
When using Python h5py to read videos and labels, the dimensions of these data will be reversed. Please pay attention to the transformation of dimensions when building your Dataset. This is a example for obtaining videos and labels using h5py:
import h5py
import numpy as np
sample_path = "yourPath/FMF-Benchmark/pixel-level/videos/SaveToAvi-4-19-21_40_52-6002.mat"
with h5py.File(sample_path, 'r') as reader:
video = reader['data'] # In MATLAB, size of video is [H W C T], but in h5py the size is [T C W H]
label = reader['label'] # In MATLAB, size of label is [H W T], but in h5py the size is [T W H]
video_clip = np.array(video[0:10], dtype=np.uint8) # Get a 10 frame video clip
clip_label = np.array(label[9], dtype=np.uint8) # Get pixel-level label for video clip
video_clip = np.transpose(video_clip, axes=(0, 1, 3, 2)) # [10 C W H] -> [10 C H W]
clip_label = np.transpose(clip_label, axes=(1, 0)) # [W H] -> [H W]
clip_label_cls = np.max(clip_label) # Get class-level label for video clipThis is an official pytorch implementation of our IEEE TCSVT 2024 paper Cross-Modal Learning for Anomaly Detection in Complex Industrial Process: Methodology and Benchmark. We propose a cross-modal Transformer (dubbed FmFormer), designed to facilitate anomaly detection by exploring the correlation between visual features (video) and process variables (current) in the context of the fused magnesium smelting process.
This project mainly requires the following python packages:
- torch
- numpy
- fvcore
- einops
- h5py
- pandas
After downloading this project, run the following code to build the codebase:
cd YourProjectPath/FMF-Benchmark
python setup.py build develop
Use the following code to test the cross-modal classification network:
python tools/test_cls.py --cfg './configs/CfgForViCu_Cls.yaml' MODEL.PRETRAINED './state_dict_vicu_cls.pth' DATA.SAMPLING_RATE 18
This project is based on PySlowFast and TimeSformer.
If you find this benchmark useful, please cite our paper
@article{wu2024crossmodal,
title={Cross-Modal Learning for Anomaly Detection in Complex Industrial Process: Methodology and Benchmark},
author={Gaochang Wu and Yapeng Zhang and Lan Deng and Jingxin Zhang and Tianyou Chai},
year={2025},
volume={35},
number={3},
page={2632 - 2645},
DOI={10.1109/TCSVT.2024.3491865},
journal={IEEE Transactions on Circuits and Systems for Video Technology}
}
This project is licensed under the MIT License - see the LICENSE file for details.